Homicidios
Este es mi primer post sobre tidy tuesday. Este proyecto, creado por Thomas Mock, publica un data set todo los martes y invita a los participantes a postear una visualización usándolo.
Para esta semana se publicaron tres juegos de datos provenientes de este blog post. La idea es mostrar el poder de ggplot para reproducir visualizaciones que encontró el autor por ahí.
Homicidios
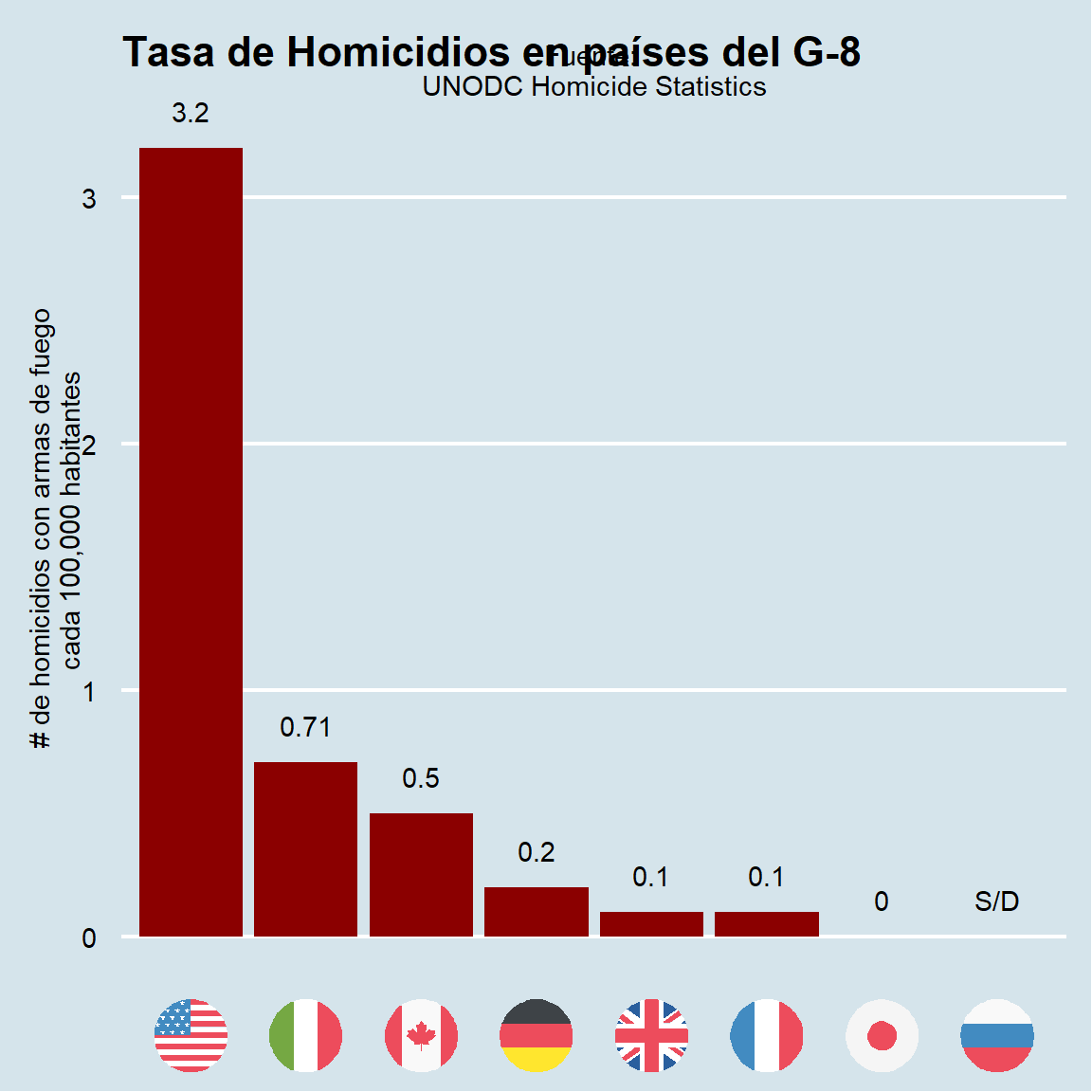
El primer dataset tiene la tasa de homicidios en 6 países del G-8:
library(tidyverse)
homicidios <- read_csv("international_murders.csv")
head(homicidios)# A tibble: 6 x 4
country count label code
<chr> <dbl> <chr> <chr>
1 US 3.2 3.2 us
2 ITALY 0.71 0.71 it
3 CANADA 0.5 0.5 ca
4 UK 0.1 0.1 gb
5 JAPAN 0 0 jp
6 GERMANY 0.2 0.2 de
Este es el gráfico original:
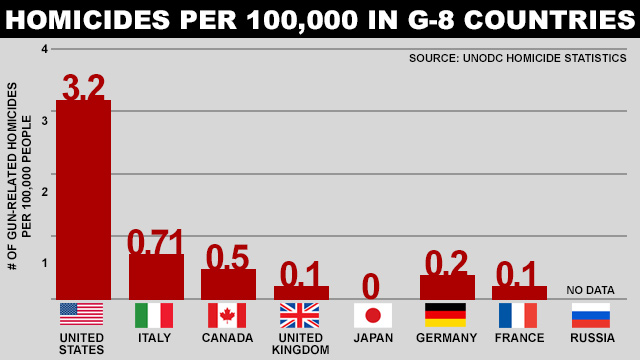
Revisando la fuente de los datos encontré esta app, sería interesante comparar a Uruguay en estos números, pero los datos no coinciden.
El diseño del gráfico es un bar chart, pero le agrega las banderas de los países y las tasas sobre las barras.
Este es el gráfico base con títulos:
# plot basico
homicidios %>%
ggplot(aes(country, count)) +
geom_col() +
labs(x="", y="# de homicidios con armas de fuego \n cada 100,000 habitantes",
caption = "Fuente: \nUNODC Homicide Statistics",
title = "Tasa de Homicidios en países del G-8.")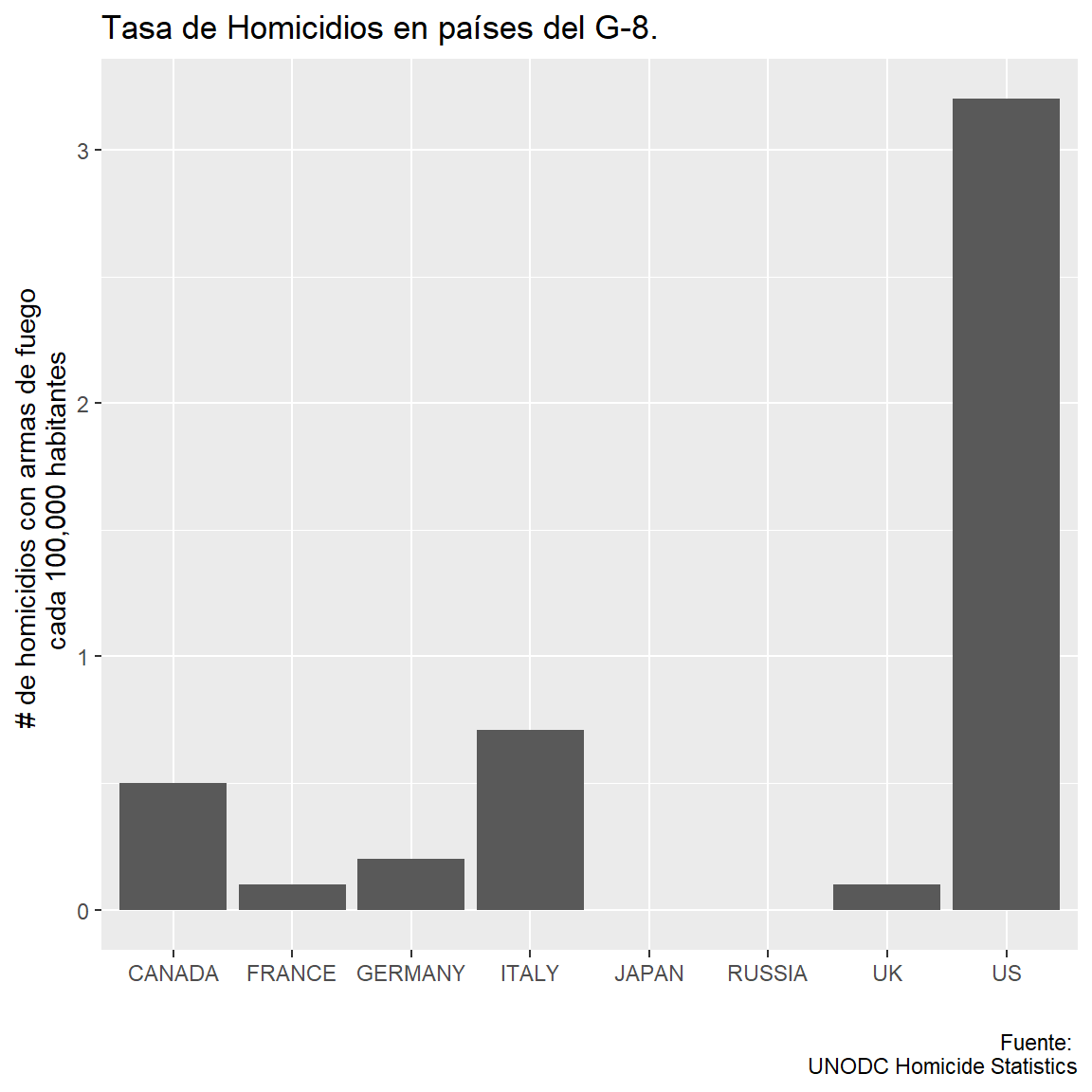
Como mapeamos el eje x a una columna de texto, ggplot la convierte a un factor. El orden en el que aparecen los países en el eje depende de los niveles del factor, por defecto es alfabético:
levels(factor(homicidios$country))[1] "CANADA" "FRANCE" "GERMANY" "ITALY" "JAPAN" "RUSSIA" "UK"
[8] "US"
Esto es algo que puede confundir a alguien que no tiene experiencia trabajando con factores: el orden de los niveles es independiente del orden en que aparecen en el data frame.
En este caso, el orden del factor es alfabético (Canadá, Francia, etc.), y el data frame está ordenado por la tasa de homicidios (descendente): US, Italia, Canadá.
Para controlar el orden en el que aparecen los países ordenar las etiquetas, usamos una función muy útil de forcats: fct_inorder. Esta función reordena los niveles del factor para que coincida con el orden en el que aparecen en el data-frame:
homicidios_2 <- homicidios %>%
arrange(-count) %>%
mutate(country_ordenado = fct_inorder(country))
levels(homicidios_2$country_ordenado)[1] "US" "ITALY" "CANADA" "GERMANY" "UK" "FRANCE" "JAPAN"
[8] "RUSSIA"
Para la versión final, agrego las etiquetas del texto con geom_text (nudge_y me permite ajustar el texto un poco para que no toque las barras).
También descubrí ggflags, que nos da una función geom_flag con el aes country para especificar el país. La coordenada y de todas las banderas la fijo en -.4.
# install_github("rensa/ggflags")
library(ggflags)
library(ggthemes)
# theme_economist
# agrego texto sobre las columnas con geom_text y nudge_y
plot <- homicidios %>%
arrange(-count) %>%
mutate(country = fct_inorder(country)) %>% # fct_inorder
ggplot(aes(country, count)) +
geom_col(fill="darkred") +
geom_flag(y = -.4, aes(country = code), size = 12) + # geom_flag
geom_text(aes(label = if_else(country == "RUSSIA", "S/D", as.character(count))),
nudge_y = .15) + # nudge, label
scale_x_discrete(labels=NULL) + # remove labels from x-axis
labs(x="", y="# de homicidios con armas de fuego \n cada 100,000 habitantes",
caption = "Fuente: \nUNODC Homicide Statistics",
title = "Tasa de Homicidios en países del G-8") +
theme_economist() +
theme(
axis.line.x = element_blank(),
axis.ticks.x = element_blank(),
plot.caption = element_text(vjust = 170) # mover caption
)plot